
A Unified Future For Computer Vision, 3D Generation & World Models
It may look like change is accelerating independently across perception, 3D generation and world models, but one general shape is forming underneath all of them.

The best paper award at CVPR 2026 went to D4RT, from Google DeepMind, UCL and Oxford, which reconstructs the geometry and motion of dynamic scenes from ordinary video. And a best paper honourable mention went to SAM 3D, from Meta, which lifts objects out of a single photo into full 3D shape, texture and layout. On the surface they have little in common - one reads the world, one writes it. But architecturally, they are nearly the same. Both build one rich latent representation, put a deliberately lightweight interface in front of it, and turn what used to be separate models into query patterns over a shared representation. That pattern owned this year’s award podium, on both sides of the camera - and that is the story you should focus on, well beyond any benchmark results.
Build one rich latent representation of the scene, then ask it questions. One encoded latent, one lightweight interface, tasks as query patterns.
Focus on this one pattern if you want to see where future developments are headed.
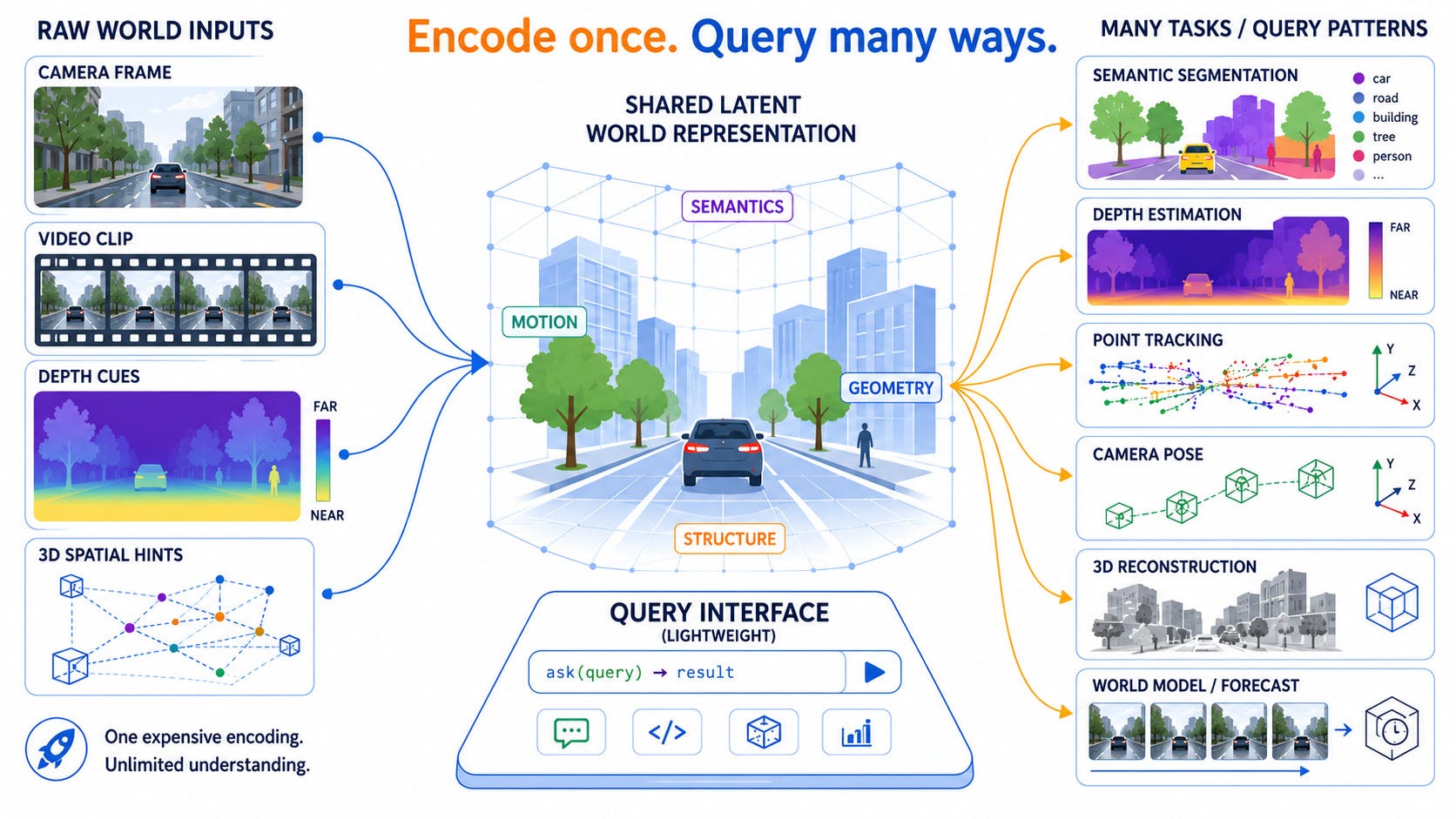
Now let’s trace how it shows up across these different domains.
For most of AI-based computer vision history, a task was a model. Depth estimation, segmentation, tracking, pose recovery, optical flow - each had its own architecture, its own training pipeline, its own output head, and systems that needed several of these capabilities were built as mosaics: a depth model feeding a tracking model feeding a fusion step, with expensive optimisation glue holding the pieces in geometric agreement. The deep-learning era changed the components but kept that assumption. Even large shared backbones sprouted a separate decoder head per task, and the task list was fixed at training time.
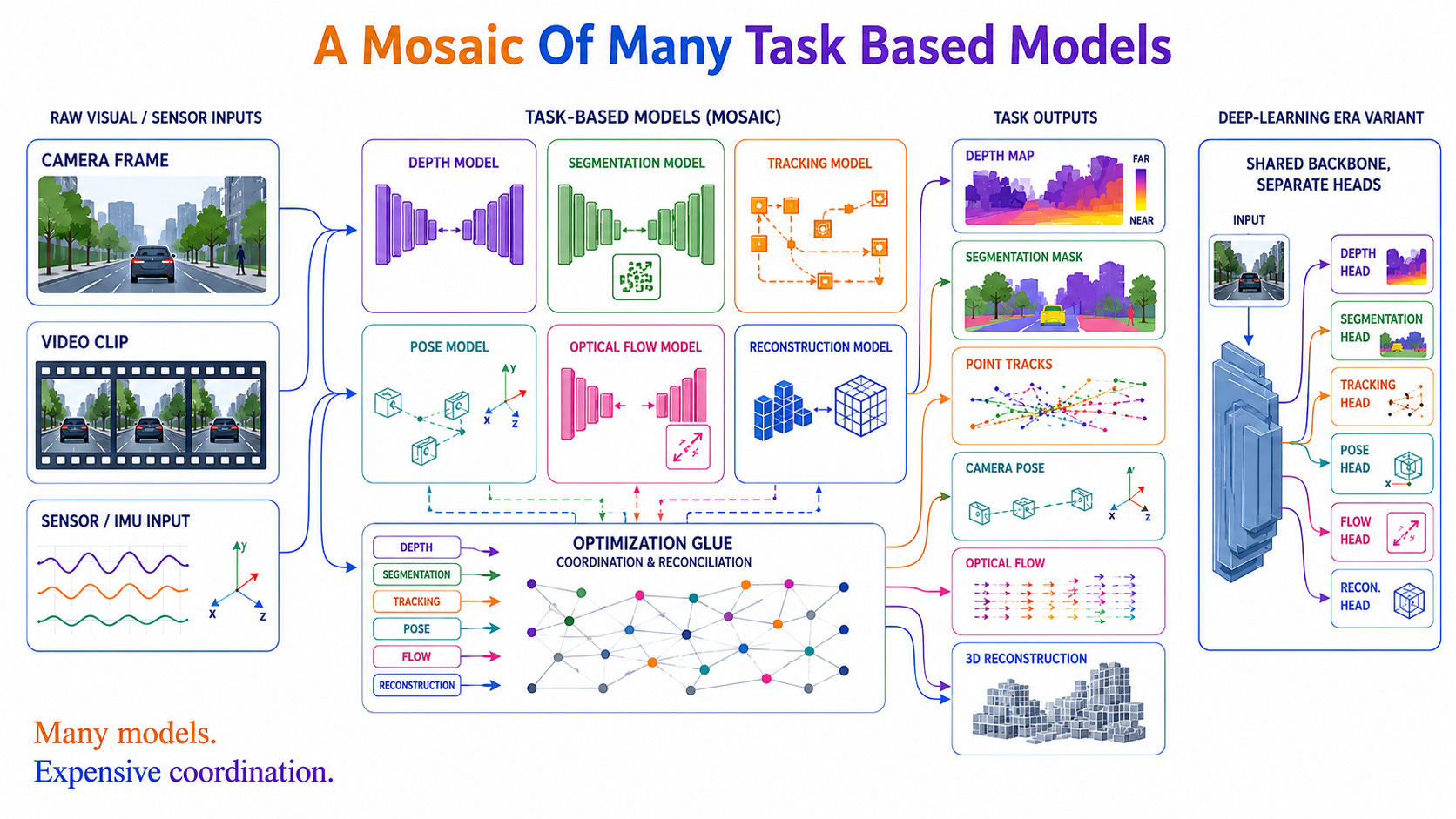
Over the past two years, this assumption has collapsed - on both sides of the camera (perception and generation alike). The replacement now has a consistent shape. A heavy encoder runs once, encoding raw sensory data into a single rich latent representation. A deliberately lightweight, general interface then sits in front of that latent, and tasks stop being models. Instead they become patterns of queries against the representation. So the expensive thing is building the understanding. And the cheap thing is asking questions of it. This architecture separates those two costs.
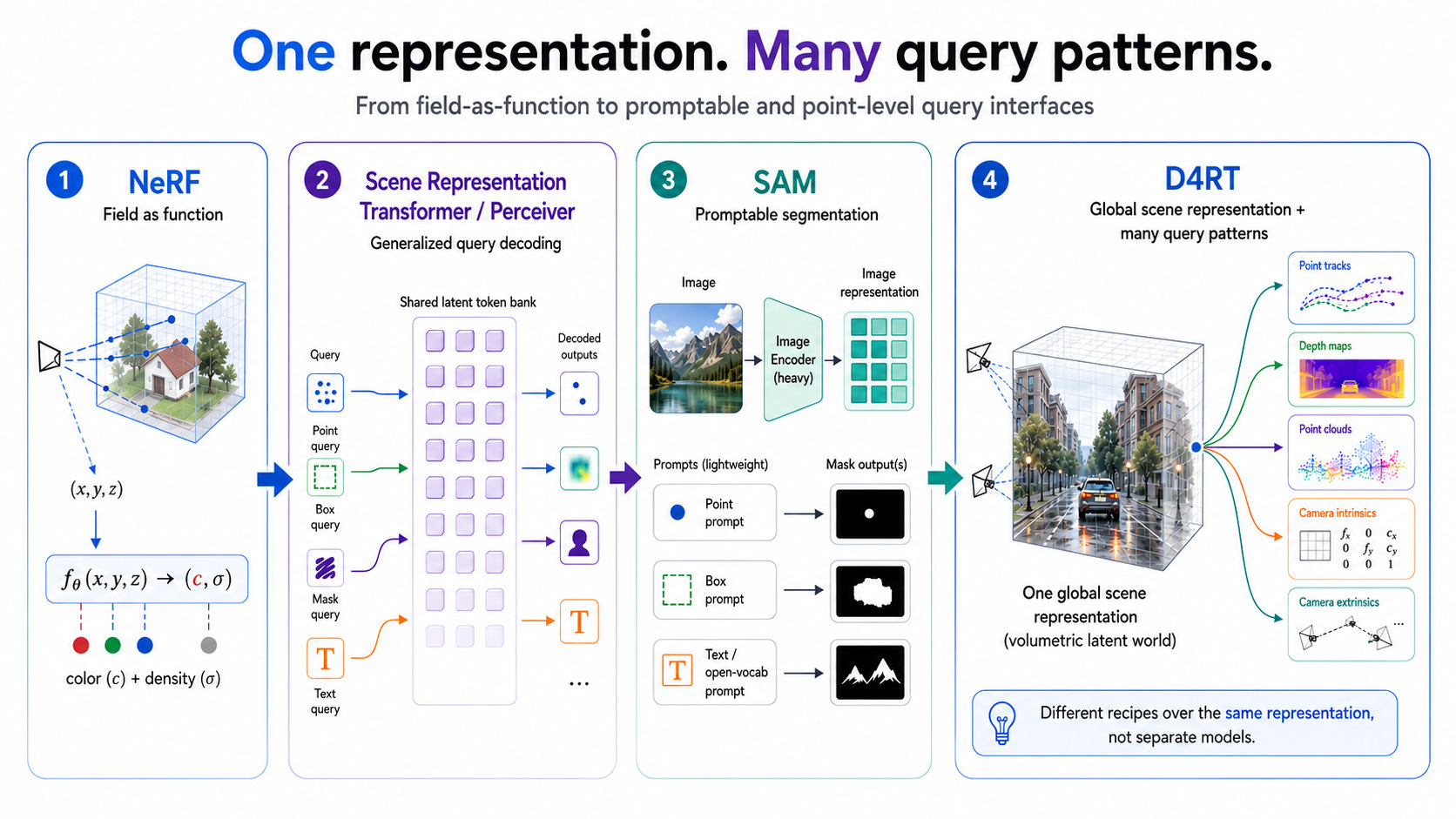
On the perception side the trajectory is easy to trace. NeRF established the field-as-function idea - feed a coordinate in, get back a value. The Scene Representation Transformer and Perceiver lines generalised query-based decoding. SAM made segmentation ‘promptable’: one heavy image encode, then arbitrary lightweight prompts (a point, a box, and eventually an open-vocabulary concept) each returning a mask. Now the current culmination is D4RT, which encodes a whole video into one global scene representation and then answers point-level queries of the form “this pixel, from this frame, at that time, in that camera’s coordinates.” Point tracks, depth maps, point clouds, camera intrinsics and extrinsics are no longer outputs of separate heads. They can be recovered as different query patterns over the same representation - now recipes, not models.
The benchmarks suggest this is not even an elegance-for-accuracy trade: in D4RT’s reported results, the unified interface is more accurate than the specialist pipelines it replaces while running 18 to 300 times faster - partly because independent queries are trivially parallel, and partly because you no longer compute dense answers nobody asked for. There are two caveats to that claim, though. These are the authors’ own numbers, and the code isn’t public yet.
However, the longer history of unified models is partly a history of negative transfer - shared representations that initially lagged the specialists they were meant to replace. NLP followed exactly that curve: unified models lagged, then crossed over, then never looked back. D4RT may not show that the crossover in vision is complete, but it does show that the crossover is now visibly underway, and an award committee rewarded it.
The generation side arrived at the same shape too, but from the opposite direction. A single pretrained diffusion or flow backbone now serves what used to be a zoo of separate systems (inpainting, outpainting, editing, style transfer, super-resolution, structural control) all expressed as conditioning patterns on one prior: a mask here, a reference image there, a depth map, an identity lock, a camera trajectory, a robot action vector. Interactive world models are the clearest case: the same generative core, with the conditioning channel swapped, becomes a text-to-video system, a camera-controlled explorable scene, or an action-conditioned simulator. Native-3D generators extend the pattern to the output side, where even the format (Gaussians, mesh, radiance field) is a decoding choice from one structured latent rather than a different model.
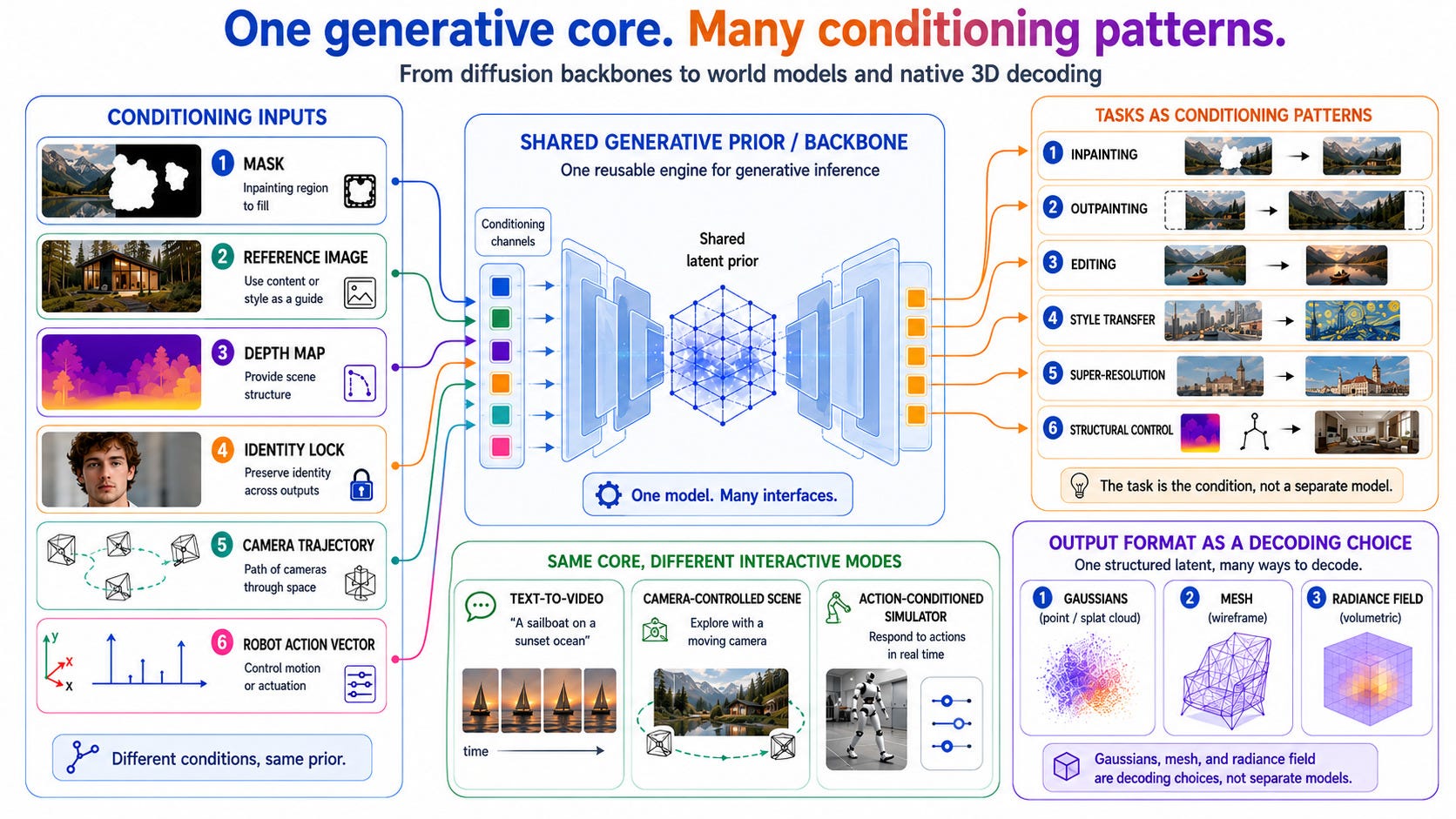
And here SAM 3D is the most telling example of all, because it doesn’t sit cleanly on either side. It is a generative model (write-side machinery) openly released and used to answer a perception question: what is the 3D shape, texture and layout of this occluded object in this cluttered photo? The paper the award committee called out alongside D4RT is blurring the line we started with at the beginning of this post - keep that in mind.
There is a precedent, of course, and that is language. Large language models made this interface shift obvious to everyone first: one pretrained model with tasks as prompts. Within roughly two years of that becoming undeniable, NLP’s ecosystem of task-specific architectures simply dissolved into a single interface. What’s happening now is vision having its own prompting moment - but this time twice over, because the pattern is landing on both the read side and the write side. Perception is becoming a read interface over a latent world-state: query what is there, where it is, and how it moves. Generation is becoming a write interface over a latent prior: specify what should be there, and condition it into existence. Same shape, opposite direction of information flow.
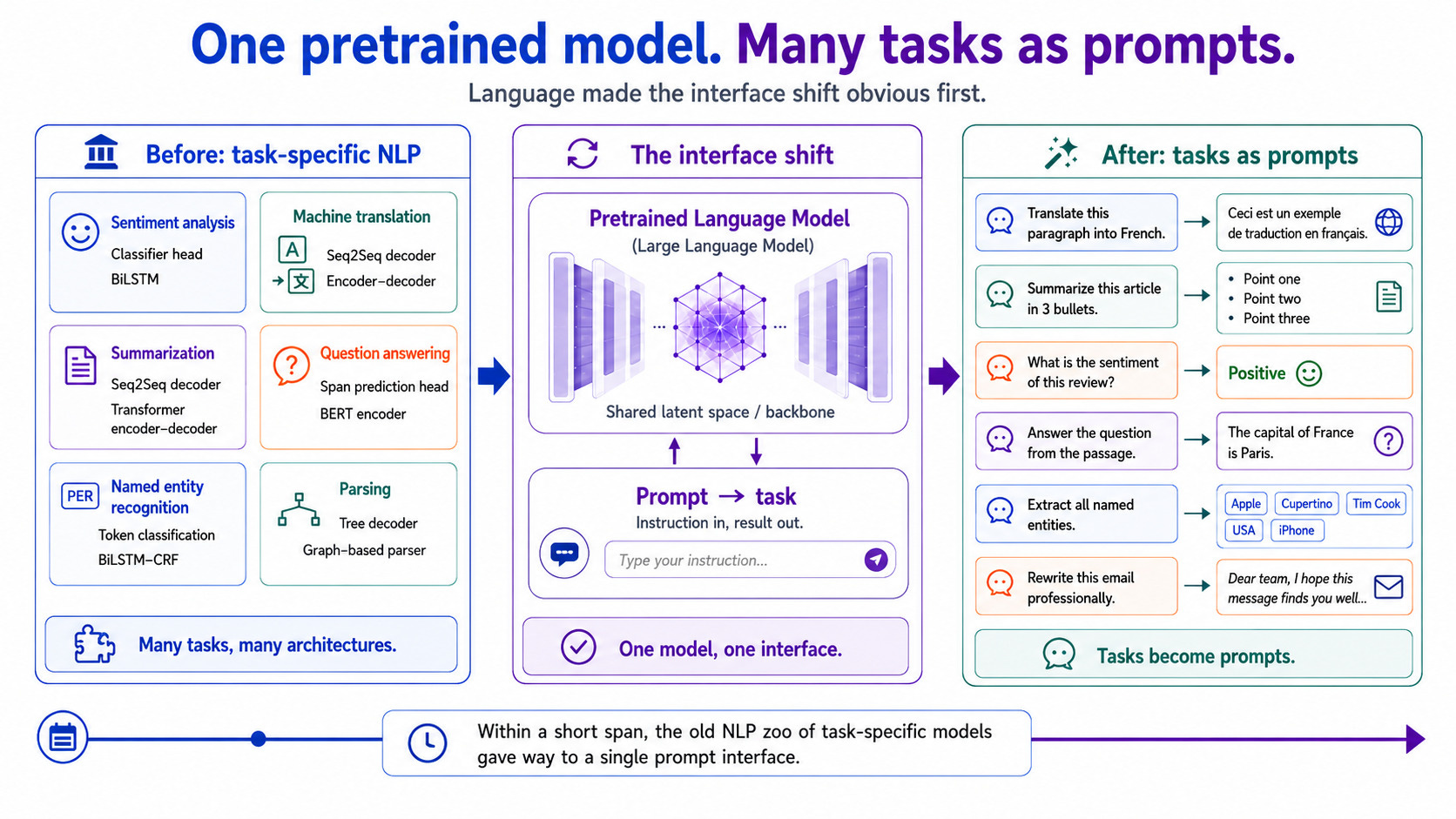
Why this pattern wins is interesting, because it’s definitely not just an aesthetic preference. This is the Bitter Lesson operating at the interface level: general mechanisms that let ‘scale do the work’ beat hand-assembled mosaics of specialists, and a query interface is the most general output mechanism there is. It’s also economics. Encode-once-query-many means training can supervise on sparse random queries instead of dense decoding. So inference cost scales with the questions asked rather than with the resolution of the world, and sparse, on-demand probing becomes the natural consumption pattern. Here you only pay for understanding once and for each question only when you ask it. Plus it’s composability: when tasks share one representation, their outputs are mutually consistent by construction, rather than reconciled afterwards by optimisation glue.
But consistency by construction cuts both ways, and ironically this is the strongest benefit we lose from the old architecture. When every task reads from one latent, any encoder error corrupts depth, tracking and pose simultaneously and coherently. The old mosaic was ugly, but disagreement between its specialists provided a free error signal - the optimisation glue wasn’t just reconciliation, it was also a sanity check. This new monolith has no internal dissent. Consistent can also mean consistently wrong, with no residual left over to flag it. That doesn’t mean this new pattern is invalid. It just means that there is at least one thing that the mosaic got for free that we no longer get: calibrated uncertainty as a first-class query, not an afterthought.
Where does this leave us?
Right now we’re sitting at the frontier of this evolution and some constraints do still remain - at least for now. The encoding step is still mostly offline and bidirectional (whole clips encoded with global attention) which makes these systems powerful teachers but not yet streaming, real-time participants. But the generation side has already given us a playbook for fixing this (distil the bidirectional teacher into a causal student), and I think it is a safe prediction that streaming, causal versions of query-based perception will follow soon using this same strategy. Query vocabularies are still ad hoc and per-model too - there is no shared standard, so “API” is generally a metaphor at the ecosystem level. And the latents themselves are relative-scale and plausibility-grade: anchoring them to metric reality, and trusting them when being wrong is expensive, these both still require some machinery that’s outside this pattern. This is exactly the no-internal-dissent problem we discussed above, but showing up during deployment. There’s also one more constraint, and it’s economic rather than architectural: the write side trains on effectively all internet video, while explicit 3D structure and robot demonstrations remain scarce by comparison - this is a point Fei-Fei Li and the World Labs team made well only last week in their functional taxonomy of world models.
So the clear pattern that’s visible now is where these two sides meet. If perception is converging on a read interface over a latent world-state, and generation on a write interface over a latent world-prior, the natural endpoint is a single representation that supports both - which is what the phrase “world model” actually means operationally, and stripped of mystique: not a video generator, but a maintained latent state of a world that can be queried and steered through general interfaces. Today the read and write sides are mostly separate models that have converged in form, but not yet in substance.
Li’s taxonomy is worth reviewing again here, because it arrives at this same endpoint from the opposite direction. She carves up world models based on what they emit: renderers output observations (pixels for human eyes), simulators output state (structure that humans and programs can both compute on), planners output actions. Her predicted endpoint (one foundation model that renders, simulates and plans, switching its output modality to suit whatever consumes it) is the fusion described above, seen from the output side rather than the interface side. The same object, based on two different cuts. But notice that the agent-world loop her taxonomy is built on has a fourth arrow that her three categories leave implicit: observations flowing back into state. That is perception. The belief update. That arrow is exactly the read interface, exactly where D4RT lives, and exactly what “a maintained latent state” means in practice. The two framings complete each other - and a taxonomy like hers and an award podium like this landing in the same week is itself a signal of where the field is turning.
I predict the substance will catch up with the form, because there are two real drivers. The first is economics: maintaining two giant latents of the same world is paying the expensive cost twice, and this whole pattern exists because the field stopped tolerating exactly that kind of duplication. The second is embodiment: anything that acts (a robot, or an agent) has to perceive, predict and plan against one state of the world. So embodied AI doesn’t just prefer the fusion, it requires it. And SAM 3D suggests the fusion process has already begun: a generative prior answering perception queries is both read and write using shared machinery, today, on the CVPR award podium. Just don’t expect the fusion to be symmetric: given the data asymmetry discussed above, it will almost certainly be pixel-led, because the write side simply has more to learn from.
What persists through all of this?
It isn’t any particular interface - there is no shared query standard yet, and every model speaks its own dialect. What persists is this new pattern. And don’t expect the dialects to fully disappear, because language never finished that job either: LLMs converged totally at the conceptual layer (tasks as prompts), only de facto at the wire layer (everyone clones the market leader’s endpoint), and not at all at the frontier, where vendors strive to differentiate.
SQL is a long-run precedent for this - a shared core plus vendor dialects that never die. But vision will be even harder, because language got its query vocabulary for free while vision’s has to be designed: coordinate frames, time indexing, output encodings. Which is why one camp is already walking a different path entirely: don’t standardise the questions at all - decode the answers into containers everyone already reads. That is the explicit-state strategy, and World Labs’ Marble is one of its clearest expressions: export Gaussian splats and collision meshes, and let the legacy 3D stack of formats, physics engines and toolchains do the interoperability work. The cost, in this post’s terms, is dense decoding - paying for answers nobody has asked for yet. (It’s also telling that where each lab stands here maps to what it ships: implicit latents suit a company selling encoders, exportable state suits a company selling worlds.)
So this future really has three branches: a new query standard emerges, the legacy formats absorb the state, or language absorbs the queries. My bet is the third. Li opens her taxonomy by declaring that the world is not made of words - and she’s right about the substrate, but the interface is a separate question. The world may not be made of words, yet the questions we ask of it may well be, with structured geometric queries surviving underneath, the way SQL sits under other representational systems. Either way, the thing to watch isn’t who wins a standardisation fight - it’s whether the query layer converges at all, because that decides if world-model capability becomes a commodity behind a clonable interface, or stays locked inside proprietary dialects. That, plus what becomes askable as query vocabularies grow (from geometry toward semantics, affordances, physics and uncertainty), is the practical way to track the actual capability frontier. The models underneath will keep churning, while it’s the pattern that will persist.
The main insight is simple: the field is reorganising around the idea that understanding is expensive and questions are cheap. Build the understanding once. Make everything else a question.