
Two Routes to the Same Manifold: Truth as a Trajectory meets Curved Inference
Damirchi et al.’s 'Truth as a Trajectory' converges on the same residual-stream paradigm I’ve been mapping in Curved Inference. Where we agree, and where the methodological debate gets interesting.

An interesting paper published on arXiv in March - “Truth as a Trajectory: What Internal Representations Reveal About Large Language Model Reasoning” by Damirchi, Meza De la Jara, Abbasnejad, Shamsi, Zhang, and Shi from the Australian Institute for Machine Learning, Monash, and Concordia - cites my Curved Inference work. They’re exploring the same question I’ve been pursuing - whether the geometry of residual stream trajectories carries a signal that conventional probing misses.
Like the Anthropic linebreaks post I wrote a while back, this is another case of an independent group traversing the same ridge from a different starting point. But this time the convergence is more direct. They’re not arriving at trajectory geometry sideways through a study of formatting boundaries - they’re explicitly working on residual stream trajectories as the substrate of LLM inference, and asking whether displacement-based geometry can detect “reasoning validity, OOD generalisation, and toxicity” better than activation-based probes can.
The short answer is - it can. And the trajectory paradigm now has independent empirical support from a credible group on dense and Mixture-of-Experts architectures up to 32B parameters. That’s excellent news. Let’s walk through where we agree, where we diverge on methodology, and what the gaps suggest for the next round of experiments.
Where the Trails Cross
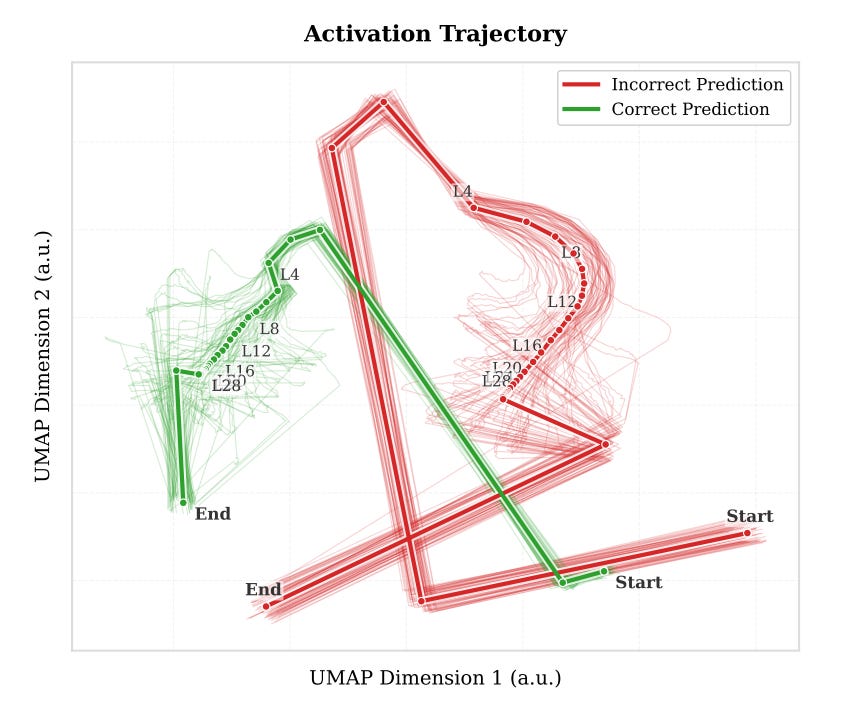
Their key moves align cleanly with the framework I’ve laid out across CI01, CI02, CI03, and the consolidated journal article. They argue that single-layer probing isn’t the right frame for understanding what an LLM is doing internally - linear probes latch onto polysemantic activations and they end up learning surface lexical patterns rather than the actual structure of inference itself. But the signal really lives in change, not state. Layer-wise displacement (Δh_ℓ = h_{ℓ+1} - h_ℓ) carries information that raw activations obscure. And when a trajectory-based classifier generalises across tasks the way theirs does, that is evidence of structural invariants that aren’t just lexical noise - this is a geometric property of how the model is processing meaning.
That’s the same paradigm shift Curved Inference argues for. Trajectory analysis displaces snapshot analysis. The residual stream becomes the canvas where you can actually watch how meaning evolves rather than sample it at one layer and hope you picked the right one.
Where they extend the picture is scale and breadth. My CI experiments ran on Gemma3-1b and LLaMA3.2-3b. They run on Llama-3.1-8B, Qwen2.5-14B, Qwen2.5-32B, and a Qwen3-30B Mixture-of-Experts model, across nine reasoning benchmarks plus toxicity detection. Cross-task OOD evaluation on dense and MoE architectures up to 32B parameters is real evidence that the trajectory paradigm isn’t an artefact of small-model behaviour. That extends the Geometric Interpretability case in a direction I’d been flagging as future work. It’s a contribution I gladly welcome and that strengthens the broader argument.
Their motivation for why displacement matters is also very close to mine. They argue that raw activations are dominated by token-specific content, which makes classifiers overfit to surface vocabulary - while displacement isolates the actual residual update and captures the geometric character of the behaviour regardless of specific words. That’s structurally the same argument I make for why curvature catches latent restructuring that surface tokens don’t.
The Cleanest Convergence is on Toxicity
Their toxicity experiment in section 5.3 is a case of independent convergence that I find really striking. They train and test on RealToxicityPrompts, then evaluate out-of-distribution on ToxiGen - a harder benchmark designed specifically to be implicit and to defeat keyword-based classifiers. On Llama-3.1-8B, displacement-based TaT hits 84.23% on ToxiGen. Linear probes get 79.62%. Raw activation trajectories - a baseline using the same LSTM but on h directly rather than Δh - get 81.99%. The gap between displacement-based and raw-activation trajectories is the interesting one. It’s the same finding I report in CI02, where curvature and semantic surface area (A′) separated transparency classes from response-type classes more cleanly than activation-based alternatives could.
The mechanism they propose for why displacement wins is structurally identical to mine too. They argue that activation-based approaches overfit to the lexical surface of the training distribution because that’s where most of the variance lives, while displacement attenuates that static background and isolates the active update. CI02 makes the same argument in different language. Geometry diverges before behaviour does, because the geometry tracks how the model is processing the prompt rather than what tokens it’s emitting.
This matters for safety monitoring. If displacement geometry can catch toxic intent obscured by benign vocabulary, the same kind of geometry should catch deception obscured by aligned-looking outputs. CI02 shows exactly that using a different behavioural target. The TaT toxicity result is, in effect, an independent replication of the core CI02 claim on a safety-relevant phenomenon the team chose for their own reasons. CI02 and CI03 are the obvious next references for them to engage with - they extend the framework into precisely the safety-monitoring territory TaT is set up to ask questions about.
The Metric Question
This is the technical point that I think matters most, and it’s also the most testable.
Curved Inference computes geometry under the pullback metric G = UᵀU, where U is the unembedding matrix that projects residual activations to logits over the vocabulary. This intuition is straightforward. The residual stream lives in some high-dimensional space whose coordinates have no inherent semantic meaning - they’re just the basis the model’s weights happened to settle into during training. If you measure distances and angles in that space using the standard Euclidean inner product, your measurements reflect arbitrary coordinate choices as much as anything semantic. You’ll see structures that may turn out to be coordinate artefacts, and you’ll miss structures that happens to be aligned with directions the standard metric doesn’t privilege.
The pullback metric fixes this by measuring geometry through the lens of what the model actually outputs. Under G, distances correspond to shifts in token prediction probabilities, directions correspond to latent semantic operations, and curvature corresponds to evolving meaning across layers. A trajectory bending under G means the model is changing what it’s about to predict, not just moving sideways through coordinate space.
TaT doesn’t use this metric. All their geometric measurements - velocity, acceleration, jerk, directional curvature, kinematic curvature, arc length - are computed under the standard Euclidean inner product on raw residual differences. Their section 4.1 reports that scalar kinematic descriptors are inconsistent predictors of reasoning validity across datasets. Velocity does best, but no single descriptor matches the base model’s accuracy reliably. Their conclusion is that scalar geometric descriptors are not enough on their own - that you need a learned LSTM to extract the signal.
From the CI perspective, that finding is reasonably predicted. Without an output-aligned metric, scalar geometric descriptors should be noisy. You’re picking up coordinate artefacts and semantically meaningful change in the same scalar quantity, with no principled way to separate them. The LSTM just ends up doing implicitly what the pullback metric does explicitly - learning to weight coordinate directions according to their relevance to model behaviour. The LSTM works. But it’s also a black box. You lose the interpretability of saying “this trajectory bent here because the model’s output distribution shifted in this specific way”.
This suggests a concrete experiment. Re-run TaT’s kinematic descriptors under G = UᵀU rather than Euclidean. Does the per-descriptor signal recover? If yes, the LSTM is recovering structure that an explicit metric would also recover, and the methodological choice between learned readout and interpretable metric becomes a question of what you want from interpretability rather than what’s possible. If no, the situation is genuinely more complex than CI currently models, and that’s a useful finding too.
Either way, this is testable. It’s the kind of test that would settle a real question about what this geometry is and what it isn’t.
What ‘Curvature’ Means
A small but important precision point. The word “curvature” is doing different work in TaT than it does in CI.
TaT defines two curvature measures. Directional curvature is a cosine between consecutive displacement vectors - it captures whether the trajectory is heading in roughly the same direction it was heading. Kinematic curvature is the magnitude ratio ‖a‖/‖v‖² - large when acceleration is high relative to velocity, capturing abrupt changes in update direction. Both are computed without a metric tensor.
CI curvature is a different object. It’s a discrete second derivative of the trajectory under G - the second-order rate of change of position with respect to layer depth, measured in the output-aligned metric. That’s the quantity that shows the localised, thematically aligned, domain-sensitive behaviour I report in CI01. It’s what defends a non-zero floor under regularisation in CI03. And it’s what diverges in advance of behavioural shift in CI02.
The distinction isn’t pedantic. A cosine between consecutive displacements tells you whether the trajectory is going the same way it was. A second-derivative-under-G tells you whether the trajectory is bending, in a sense anchored to the model’s own output behaviour. The TaT choice is a coarser measurement that loses information the CI approach preserves. When CI papers talk about curvature, they specifically mean the second thing.
Detection vs. Necessity
There’s a deeper structural difference in what each framework is set up to ask.
TaT’s LSTM is a detector. It tells you whether displacement geometry carries enough signal to classify reasoning validity, OOD generalisation, or toxicity. That’s good evidence the geometry is informative - that something structural is there to be picked up. But it does not easily tell you whether the geometry is required for the capability it correlates with. A correlation between displacement and reasoning validity doesn’t imply the reasoning depends on that displacement.
CI03 was designed to ask the necessity question directly. The setup added a curvature regularisation term to the SFT loss and progressively strengthened it - λ·ℒ_curv with κ-clamp targets ranging from 0.000 to 0.900. If curvature were merely a correlate of computational self-modelling rather than a structural requirement, regularisation should flatten it cheaply. It didn’t. The model appeared to defend a non-zero curvature floor at substantial optimisation cost - outputs shortened by 23%, perplexity spiking transiently by 800% before settling at 190% above baseline, and gradient norms requiring clipping. And when curvature finally did approach the floor, MOLES self-model classification degraded - from ~84% accuracy at moderate clamps to 66% at 𝜅 = 0.90.
That’s a different kind of result than the LSTM produces. It’s evidence of an apparently defended geometry. Structure the optimiser preserves even when explicitly penalised for keeping it. TaT, as currently set up, doesn’t have an apparatus for that question. The two methods are answering different questions, and both are legitimate.
Necessity work is the natural next step in the trajectory paradigm, not a competitor to detection. CI04, which I’ve sketched out, extends the necessity argument through layer-selective ablation - intervening on curvature at inference time rather than during fine-tuning. Interestingly, TaT’s apparatus could contribute here. Their toxicity results suggest they also have the detection capability that necessity tests need as a starting point.
Where This Leaves Us
Two independent frameworks, with different theoretical scaffolding, both converging on the same conclusion - trajectory geometry is the right level of analysis for understanding what these models are doing internally. TaT gets there through the Privileged Basis Hypothesis. CI gets there through the pullback metric and second-order curvature. Both end up arguing that residual stream displacement carries a signal that probes miss, and both end up showing it across different domains.
The methodological disagreements that remain - whether to measure under Euclidean or pullback, whether scalar metrics can recover the signal an LSTM finds, where exactly the line between detection and necessity sits - aren’t framework-level disputes any more. They’re empirical questions, with concrete experiments that could settle them.
That’s where independent convergence gets really useful. Not as confirmation that we’re both right, but as a way to sharpen the questions to the point where one of us turns out to be wrong about something specific. That’s the part of the work I’m most interested in.
To the Damirchi team specifically - the kinematic-descriptors-under-G experiment is something I’d love to see your apparatus run. You have broader scale and benchmark coverage than I currently do, and the metric question is worth settling rather than leaving as a methodological background assumption. If you’d find it useful, all the CI tooling is open source on the FRESH-model GitHub repo, including the pullback metric implementation and the curvature/salience pipelines I’ve been using.
More broadly - if you’re working on geometric interpretability, trajectory-based methods, or the intersection between mechanistic and geometric analysis, I’d love to hear whether the metric question shows up in your experiments. It’s the kind of question independent replication would settle quickly.
Damirchi et al.’s “Truth as a Trajectory” is available on arXiv. The full Curved Inference series, including the consolidated journal article, is at robman.fyi/curved-inference. All experimental code, prompts, and metrics are open source on GitHub.