
Retraining Is The Answer
'Retrain the workforce' it seems is the one answer everyone agrees on. But like Douglas Adams' famous 42, I think it's the right answer to a different question, from a different era.

In The Hitchhiker’s Guide to the Galaxy, a race of hyper-intelligent beings build a supercomputer to settle the Ultimate Question of Life, the Universe and Everything. The machine, with a fine sense of irony and a perfect match for today’s AI world, is called Deep Thought. It runs for seven and a half million years and produces an answer: 42. The answer is fine. The catastrophe is that nobody ever actually worked out what the question was, which makes the answer useless - so Deep Thought has to design a second, even bigger computer to figure that part out.

I keep thinking about that joke when I read the AI-displacement policy discussions. We have built actual deep-thinking machines now, and the answer that’s being handed the workforce is “just retrain”. It’s confident, it’s everywhere, and at least we don’t have to wait 7.5 Million years for this answer - but it has the same problem as 42 - it’s a perfectly good answer to a question nobody has bothered to specify. Retrain into what, exactly, and for how long before that retraining expires?
If you read my last post, you’ll remember it ended on just that question. That post has a decidedly US based flavour. Connecticut is weighing an automation tax with the revenue earmarked for worker retraining. Tom Steyer’s California platform wants an AI Worker Protection Administration. Sam Altman’s own white paper proposes safety-net triggers for AI-driven displacement. And across all of it, from the bank chief economists to the policy shops to the lab CEOs hedging their bets, sits one single shared assumption:
When AI takes the job, you retrain the worker into a new one.
It is a rare position that Bernie Sanders, Donald Trump’s Commerce Department and Anthropic’s policy team can all nod along to. And this should be the first clue that few people have looked at it very hard.
Retraining is not a bad idea in the abstract. It has worked in previous eras, in the right conditions. The problem is that the conditions it needs are precisely the ones this technology is dismantling. It only works when the destination role lasts longer than the training cycle.
The half-life problem
Lets start with the cleanest full example we have, because it is one that the industry held up as a destination role barely three years ago: the prompt engineer.
In early 2023 this was a serious job. Anthropic posted a “Prompt Engineer and Librarian” listing with a range running to $375K, and the trade press treated it as the first genuinely new white-collar profession of the AI era. Courses appeared. Career-change guides appeared. “Learn to prompt” was, for about eighteen months, an actual retraining answer.
Then look at the decay. By 2025 the skill had been absorbed and renamed - the live discipline was now “context engineering”, which is the same stack but one level up - managing the whole window of tools, memory and retrieved data rather than wording a single instruction. Gartner was telling AI leaders to appoint a context-engineering lead. Andrej Karpathy was endorsing the term as the better description of the real skill. And then by 2026 even that had moved again, toward the orchestration of multi-step agents, which Cursor and Claude Code now bundle directly into the editor as a default feature rather than a profession. Now the single “/goal” command in Claude Code is pushing the frontier again.
So the observed half-life of this particular “new role” was something like - essential six-figure speciality → to subsumed skill layer → to embedded layer in the tooling - all in under three years. Anyone who retrained into prompt engineering in 2023 to escape displacement had to retrain again in 2025, and again now.
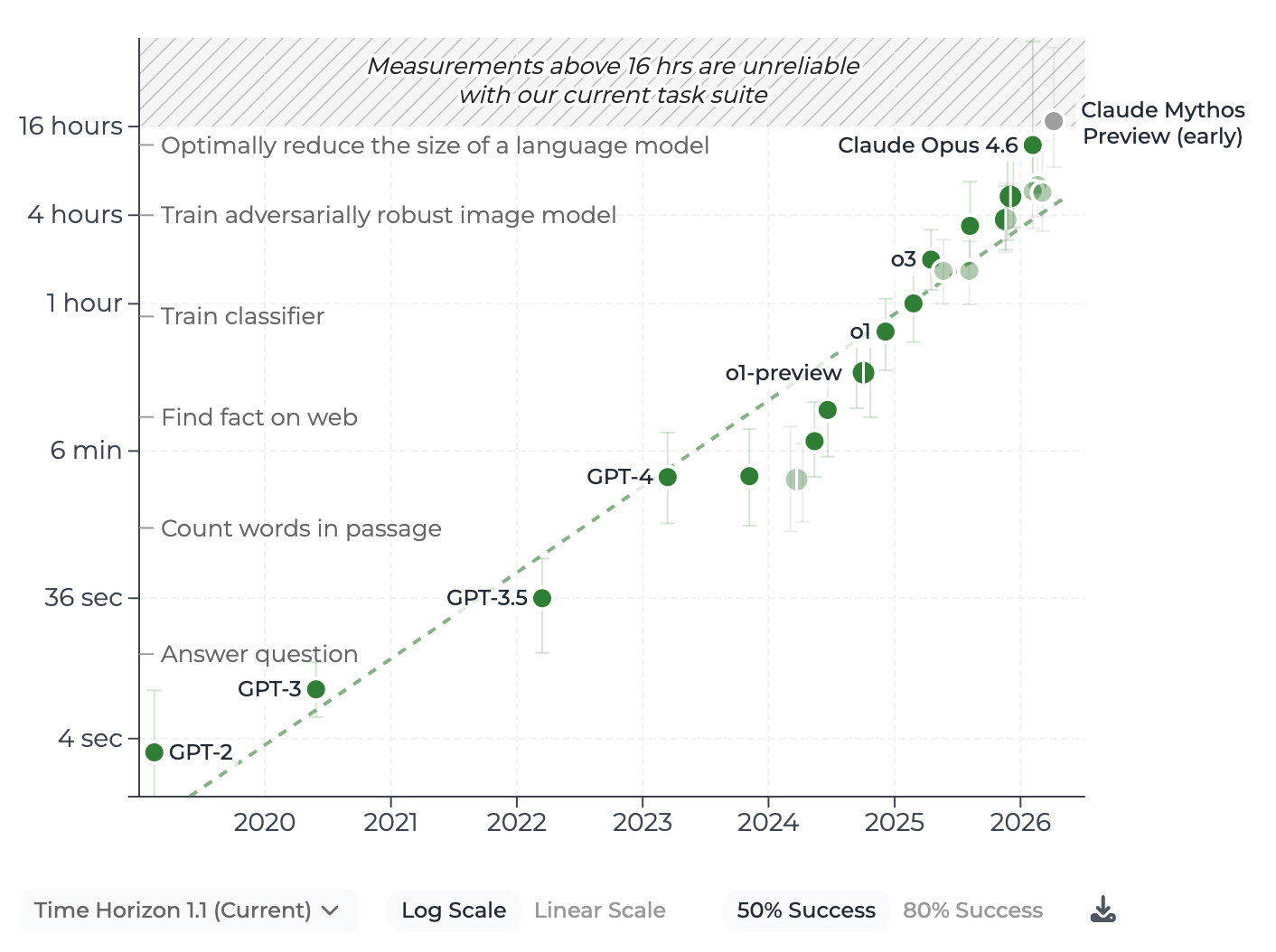
That compression isn’t a fluke either. It is being driven by the same capability curve that produced the displacement in the first place. METR’s autonomous-task time horizon (the length of task a model can finish on its own at a 50% success rate) has been doubling roughly every seven months since 2019, and their January 2026 update found the trend continuing in line with that history. In rough numbers: a few seconds for the GPT-3-era agents of 2020, around five minutes for GPT-4 in 2023, roughly forty minutes for o1 in late 2024, and on the order of twelve hours for the frontier models of early 2026.
Hold the exact figures loosely - I’ll come back to how shaky the top end of that curve is. The point survives even the conservative reading. Each doubling collapses another layer of the “new role” stack faster than a human can climb onto it. There is no doubling interval at which retrain-and-stay becomes a stable career, because the rung you retrained onto dissolves before you’ve finished standing up.
Human capabilities don’t double in months
Here is the part the policy language skips over.
Really mastering a new technical role to professional standard is the work of years, not months. Meanwhile, a model’s time horizon can already double in months. A person’s professional competence cannot. The “you’ll simply need to keep learning” answer silently assumes a human learning rate that compounds at the same speed as model capability, but it doesn’t. It can’t. That isn’t a motivational failing. It’s a biological and cultural reality.
And the cost isn’t only cognitive. Doing this three or four times in a decade (each time having watched the last speciality dissolve under your feet) carries a real psychological toll, and we already have some data on it. Population-wide studies of displaced workers find lasting harm: one analysis using administrative records found a 15 to 16% long-term rise in mental-health outpatient visits among workers who lost jobs to mass layoffs, with effects still visible years later. Clinicians are now proposing a name for the AI-specific version of it directly. A 2025 paper proposes “AI Replacement Dysfunction” (AIRD) - the anxiety, identity confusion and loss of occupational meaning that arrive when your work is what’s being automated. We used to see this pattern in manufacturing towns after the 1980s. It is arriving now in knowledge work, faster than the institutions built to retrain anyone can respond.
The asymmetry that retraining relies on
The deeper objection is harder to say out loud, because it sits on the far side of a threshold most retraining policy has not yet absorbed.
The entire case for retraining rests on one assumption that has reliably held for the whole industrial era:
Humans carry a general-purpose intelligence, so we can generalise onto a new task faster than a narrow tool can be built to do it for us.
That asymmetry is what made “learn the next thing” a viable hedge for two hundred years. It’s the reason that the loom didn’t end our economic viability - we moved up the stack quicker than the machines could follow.
Now the agentic trajectory is closing that gap. The explicit goal the labs keep stating (autonomous researchers, “innovator-class” systems that can take on novel problems) literally is the goal of a model that generalises across new tasks at something near human speed. And the moment that lands, “the ability to learn new things quickly” stops being a uniquely human hedge. The hint is in the industry language - we literally “train” a model. And increasingly, there is no role you can retrain into faster than the model can learn to do it.
That is the version of the argument that really has teeth. Retraining doesn’t fail here because it’s expensive, or unfair, or politically clumsy, although sometimes it is all three. Instead, it fails because the once scarce input that it always depended on (fast human generalisation) is no longer scarce. You cannot retrain your way out of a situation whose defining feature is quite literally that “retraining is the commodity being automated”.
What this argument doesn’t prove
It’s worth being honest about the soft spots in the argument I’ve just laid out.
First, the capability curve. I’ve relied on METR’s time horizon above, but the top of that curve is genuinely fragile. The longest-task estimates rest on success across a handful of tasks in the longest time bins, so a few percentage points of noise can swing the headline number hard - and METR themselves flag that the confidence intervals remain very wide. There’s also an active debate about whether the doubling briefly sped up in 2024 and is now reverting. So treat “twelve hours” as very roughly indicative, not gospel. Yet the structural argument does not need the curve to be steepening to have an impact. It only needs the half-lives of new roles to be shorter than the time a human takes to retrain, and that point is valid even on the slow reading.
Second, the displacement itself isn’t settled in the aggregate data - yet. Through 2024 some careful work pointed the other direction - Johnston and Makridis found augmentation, not replacement, as the dominant pattern, and Yale’s Budget Lab tracker still shows no dramatic break. But as we discussed in my last post, these are all based on data from before the agentic-coding shift at the end of 2025. The real data on this will only start to arrive in just over a week from now and will likely take several quarters to be clear one way or the other.
So, the falsifiable version:
Re-skilling programmes funded now should show falling, not rising, time-to-obsolescence for the roles they train into. If a 2026 cohort retrained into an “AI-resistant” speciality is still in that speciality in 2029, I’m wrong about the half-life. What would prove this wrong: a genuinely durable new role category emerging and staying durable for several years, the way “electrician” did after electrification.
The general-generalisation threshold should keep approaching, not stall. My deeper claim depends on models closing the fast-learning asymmetry. What would prove this wrong: capability plateauing well short of human-rate generalisation - which is close to Demis Hassabis’s position that AGI needs “one or two more breakthroughs” and is years out. If he’s right, the loom analogy gets more time to hold, and ordinary retraining remains a live strategy rather than a slogan. But even his 5-10 years is still really a near term horizon that we should be taking seriously!
So retrain into what?
That’s the question the word “retraining” is supposed to answer but it never does. Every serious version of the policy (the automation taxes, the worker-protection agencies, the lab CEOs’ own white papers) assumes a stable destination role on the other side of the training. And the AI capability curve is the thing removing that assumption, one collapsed speciality at a time. The retraining era is over. We just haven't updated the policy to match.
And this loops back to where my last post left off. Watch what they build, not what they say. The same companies funding the enterprise-deployment layer that makes roles cuttable are also the ones proposing the retraining safety nets. That isn’t a contradiction. It’s the exact same bet, hedged from both ends - sponsor the cushion now so you’re seen to have offered one, while building the thing that makes the cushion necessary.
The honest answer to “retrain into what?” is that nobody pushing this policy has an answer. And until they do, “just retrain” is not a plan. It’s simply a way of avoiding the harder conversation.
Your video nails it. Dark.