
Only A Fool Brings AI Optimism To An Economics Fight
The history of automation led to job growth because displaced workers could climb to the next layer. But AI may be targeting that very climbing mechanism itself.


Recently I’ve written about the flawed methodology in much of the AI-job-boom narrative, why the new “calm down, AI won’t take your job” messaging gets it wrong, and why retraining isn’t the answer. I also asked if you’re the horse in this story.
All of these have been dancing around one specific point.
Now it’s time to look at that underlying idea, and how the real discussion here is not about the technology. This is where two conversations constantly get blurred. So let me be clear up front: I am an AI optimist. I use these tools daily and I spend a lot of time exploring their internals. But none of that is what this post is about. Instead, it’s about why this new capability is structurally different, and how this interacts with the way our economy has developed.
But the capability side and the economic side don’t always play nicely, so it’s important to recognise:
Only a fool brings AI optimism to an economics fight
The background story: For over 250 years, automation has had the same shape. Each wave cleared work from below, and the displaced people climbed up to a new layer above it. Farm labour to factory work. Factory work to clerical work. Clerical work to knowledge work. The shape stayed the same because there was always a layer above to climb up to, and the people that were displaced generally had the operational capacity to do that climbing.
This time the shape has changed. I know that as soon as people say “but this time is different” they’re labelled as “doomers” and everyone points to all the previous examples of “this time” failures. But hear me out and focus on the “structural” point.
The shape has not changed because AI is more capable in the abstract - that has been claimed in previous revolutions, but the wedge just kept on working. This time is different because the thing being targeted is the structure of the climbing mechanism itself.
That is the idea that you need to seriously consider. And the reason it’s worth taking seriously is because trillions of dollars have been allocated to one goal that makes this real (regardless of your view on where we’re up to on this path) - and that is AGI (Artificial General Intelligence).
But the AI labs and most public commentary have grown to use a flattened definition of AGI. A definition that makes this “change in shape” harder to track and see. In fact, the AGI term has been used to describe two quite different things, and they both impact the labour-market story in different ways. So the right place to start is with the two AGIs.
Which AGI?
The G in AGI stands for “General”. Simple enough. Except here, as I mentioned, “general” can mean two different things. And the AGI literature meant “both at once” for forty years, before the labs appeared to cut one out.
The first sense is breadth. Performance across many tangible tasks in many domains. The “AI as ‘good enough’ at pre-defined or economically valuable tasks” framing. This is what multi-task benchmarks like MMLU or HELM measure. It’s what OpenAI’s 2018 Charter operationalises as “highly autonomous systems that outperform humans at most economically valuable work”. Call this one task-AGI.
The second sense is generalisation itself - the cognitive process. The capacity to abstract, transfer, compose, and adapt to novel circumstances. The same operation working across previously unknown problems. This is what prior-controlled benchmarks like ARC-AGI measure. It’s how much new performance the system extracts per unit of new data. Call this one process-AGI.
The labs focused on task-AGI for good reasons. It’s measurable. It’s tractable. It’s economically useful early on. Process-AGI is the more complex one. It’s what the founding generation of AGI researchers pointed at - and what the rigorous formal critics never abandoned.
These are not opposites. The seminal AGI literature held both as a conjunction. When Ben Goertzel and Cassio Pennachin coined “AGI” in their 2007 volume, their working definition coupled both senses: “general scope AND is good at generalization across various goals and contexts”. Allen Newell and Herbert Simon’s 1976 Physical Symbol System Hypothesis defined “general intelligent action” as both “the same scope of intelligence as we see in human action” AND “adaptive to the demands of the environment”. McCarthy, Russell and Norvig, Pei Wang’s NARS work - for four decades the seminal research work held both definitions.
Then something happened. Or perhaps more accurately, something didn’t happen.
Flattening AGI
Between roughly 2014 and 2018, the industrial usage of AGI slowly stopped meaning both and started meaning task-AGI alone. Not because someone argued for it. But because nobody really argued for the other side when it mattered.
Nick Bostrom’s Superintelligence (September 2014) stipulated task-AGI as a definitional shortcut for a popular book about safety. The Future of Life Institute’s Puerto Rico open letter (January 2015) redirected academic attention from “what is AGI?” to “how do we make AGI safe?” The task-AGI stipulation rode along, and the “economically valuable work” wording that would crystallise three years later in the OpenAI Charter is pre-figured here. DeepMind’s DQN paper in Nature (February 2015) demonstrated a single algorithm clearing 49 Atari games and called it “a central goal of general artificial intelligence” - not an argument for task-AGI but an operational demonstration of it. Three months later, LeCun, Bengio and Hinton’s Nature review codified deep learning as cross-domain successful. Then OpenAI launched in December 2015 without using “AGI” - the category term they chose was “digital intelligence”. And by the time the 2018 OpenAI Charter crystallised the framing as “highly autonomous systems that outperform humans at most economically valuable work”, the breadth framing had just become institutional common sense.
Through the same window, the academic critics who held process-AGI as the actual question kept publishing. José Hernández-Orallo’s formal defence in August 2014, expanded to AI Review in 2016 and culminating in The Measure of All Minds at Cambridge in 2017. Goertzel kept the conjunction explicit in his 2014 JAGI survey. François Chollet articulated the formal counter-argument in “On the Measure of Intelligence” in November 2019 - years after the cascade was complete. Published, cited, influential in academic venues - and lost to the popular and industrial conversation entirely, because nobody pushed back hard enough when that conversation actually happened.
The most revealing detail comes from DeepMind themselves.
In 2024, Morris et al. published “Levels of AGI for Operationalizing Progress on the Path to AGI”. The paper finally articulates the principle explicitly.
Principle 1: “Focus on Capabilities, not Processes”.
When they cite an authority for that choice, they don’t cite Legg-Hutter 2007. They don’t cite the DQN paper. They don’t cite any source between 2007 and 2022. Instead they walk all the way back to Turing in 1950:
“We agree with Turing that whether a machine can ‘think,’ while an interesting philosophical and scientific question, seems orthogonal to the question of what the machine can do - the latter is much more straightforward to measure and more important for evaluating impacts”.
DeepMind needed an authority for the task-AGI principle. But there wasn’t one. So they reached back 74 years to Turing.
That detail is revealing. The flattening was never really argued. Instead, task-AGI just crowded out the process-AGI sense through demonstration, safety-conversation redirection, and popular-science simplification - while the academic critics kept publishing into a conversation that had already moved.
To be fair to the labs, process-AGI is genuinely hard to measure. ARC-AGI is the only widely-recognised process-leaning benchmark. So the labs chose the measurable question. But the cost was structural silence on the process-AGI question (whether the cluster is targeting the operations that knowledge work runs on) even as the capability that is evolving most clearly looks like exactly that.
This post is reclaiming the full definition that the seminal authors held for forty years and what the rigorous formal critics never abandoned. The G in AGI is really doing two different jobs and both are at work - right now.
Where each one stands
Yes both are in motion. Task-AGI is arriving on the schedule the labs predicted (see the OpenAI roadmap that leaked in 2024 discussed below - this is playing out as projected). Process-AGI is harder to measure cleanly, but the operational evidence of it is visible if you look carefully.
A frontier model in 2026 writes coherent synthesis across multiple medical papers. Drafts strategy memos. Generates working code from a specification. Builds a multi-step plan to integrate a new system into an enterprise stack. Runs autonomous research workflows for hours without supervision. These are not benchmark tasks. They’re knowledge work - drafting briefs, reconciling figures across documents, sequencing multi-step rollouts, checking outputs against criteria. The model is doing enough of the operations that the basic-generalisation question is no longer academic. ARC-AGI-1 (visual abstraction puzzles, designed to test the cognitive process directly) is saturated. ARC-AGI-2 is approaching saturation. ARC-AGI-3 (interactive reasoning under agentic conditions) is at less than 1 percent but agents are only just starting to engage with it.
The original AI tradition wouldn’t have been surprised by all of this. Newell and Simon’s frame treats symbolic manipulation and physical embodiment as separable problems with separable timelines. While the labs flattened this distinction in their public framing through the 2010s, treating AGI as one bar to cross rather than two technical problems with different timelines. The flattening made corporate messaging cleaner. But it also made the asymmetric arrival harder to read for anyone working from this definition.
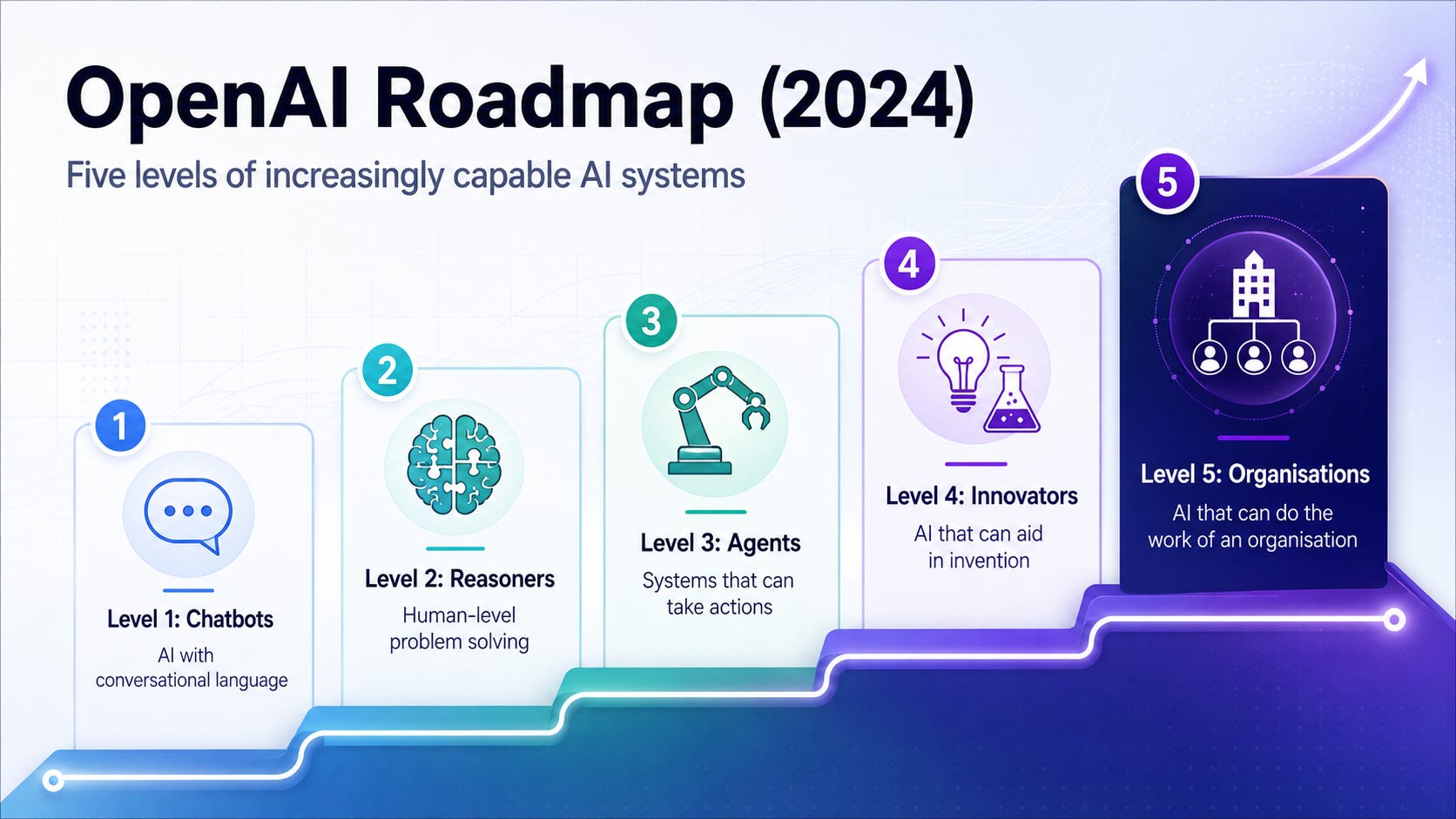
The OpenAI roadmap from 2024 frames progress in task-AGI terms - levels of task capability. Five levels in total:
Level 1: Chatbots, AI with conversational language
Level 2: Reasoners, human-level problem solving
Level 3: Agents, systems that can take actions
Level 4: Innovators, AI that can aid in invention
Level 5: Organisations, AI that can do the work of an organisation
When the roadmap was leaked, Level 1 was the standard. Reasoners and Agents were aspirational. Innovators sounded like science fiction.
Two years later:
Reasoners are well established. Claude Opus 4.x, GPT-5.x, Gemini 3 Deep Think - multiple frontier models running explicit chain-of-thought at olympiad-level performance on mathematics, physics, and chemistry.
Agents are in production across all three top US labs. Claude Code shipped persistent goals in early 2026. OpenAI’s Codex followed inside weeks. Google’s Antigravity and Gemini Spark are both Stage 3 agent products by mid-2026, with Spark running 24/7 in the background on Google Cloud.
Innovators are also visibly emerging. Chris Hayduk demonstrated GPT-5.5 running 150 continuous hours of autonomous research on a protein-folding architecture, no human intervention. OpenAI’s internal reasoning model disproved an 80-year-old Erdős conjecture in discrete geometry in May 2026, verified by external mathematicians - the first time a general-purpose frontier model has autonomously solved a long-open problem central to a mathematical subfield. Google’s ERA system, published in Nature, autonomously generates working scientific code across multiple research domains.
The first three stages are now clearly in motion, and credible early evidence is appearing around the fourth.
When a roadmap with that track record points at Level 5 (organisations that can do the work of an organisation) taking task-AGI seriously means taking one-person and zero-person organisations seriously. Not as science fiction. But as the next level whose arrival has been compounded against four times in a row. And this fifth level may now be the gateway to process-AGI.
How work has moved for 250 years
To understand why this matters, in the way it matters, you need to look at how work has also been evolving, over the last 250 years.
Standard “sectoral framing” bundles together work that runs on completely different things. Agriculture, manufacturing, services. For example a nurse and an engineer both sit in “services” but they’re doing structurally different work. For the question of where AI capability is actually landing, a different slice and dice is much more useful.
Three categories:
Physical work: tasks that move matter, exert force, depend on muscular effort and rough motor coordination. Farm labour, foundry work, line construction.
Embodied work: tasks that require sustained sensory-motor integration, learned dexterity, contextual judgement. Skilled trades, surgery, expert craft, much of nursing.
Symbolic work: tasks dominated by abstraction, comparison, planning, synthesis, verification. What knowledge work runs on.
Run that slice and dice across the US census data from 1775 to 2025 and the shape is monotonic and large. In 1775 around 92% of US work was physical, 5% embodied, 3% symbolic. By 1900, roughly 65/18/17. By 1925, 55/22/23 - symbolic crossed embodied for the first time. By 1975, 30/29/41. By 2025 the mix is roughly 20/30/50.
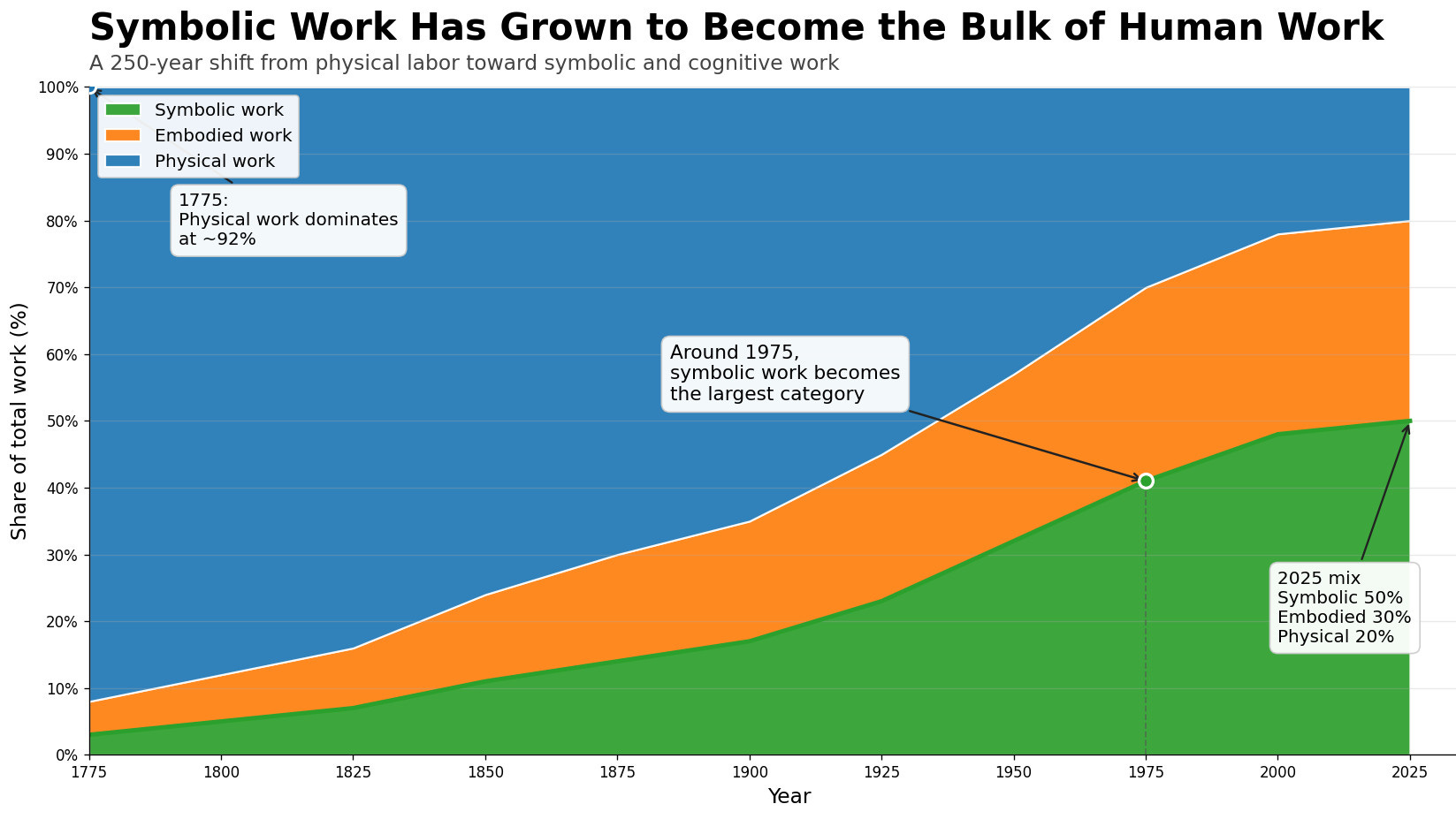
Symbolic share grew seventeen-fold over 250 years. The standard “services growth” framing understates the shift because services bundles embodied work alongside symbolic work. Pulling those apart sharpens what was actually happening. Work concentrated at the level of symbolic operations went from a small minority to the majority.
NOTE: This decomposition uses Carter et al.’s Historical Statistics and IPUMS-USA occupational microdata for the historical record and BLS OEWS for the present. The cut between physical, embodied and symbolic work is applied per a methodology note I’ll publish separately.
The mechanism that produced the shift is what matters here. Each automation cluster (agricultural mechanisation, factory mechanisation, software automation of clerical work) cleared specific work from the category below. Displaced labour pushed upward into the next, more symbolic category. Goldin and Katz call the supply-side version of this the educational ratchet. Each generation acquired more years of formal education than the last. The economy absorbed the more-symbolic capacity that produced. Mokyr’s framing covers the demand side: useful knowledge accumulated, and economies that could distribute and apply it grew the categories of work that ran on it.
This wedge worked because of a particular feature of human capacity. François Chollet, working in machine learning, defines intelligence as efficiency at acquiring new skills rather than possession of existing skills. Each cluster transition demanded that displaced workers acquire skills at the next layer up. The wedge worked because human skill-acquisition efficiency is general enough to follow the upward ratchet across categories. It’s the same operations doing the acquiring, again and again, at each new layer.
Read that one more time. Slowly.
The thing that let workers move up the wedge for 250 years was the operational capacity to acquire skills at the next abstraction layer. That capacity was the ladder’s step we stood upon. Every transition assumed it. Every retraining program assumed it. Every assumption about how economies absorb technological change assumed it.
But what happens when a new technology cluster arrives that operates at exactly that level?
There may be no next layer to climb up to
The AGI technology cluster targets this ladder’s step.
Earlier clusters displaced specific skills. The wedge worked because workers could acquire skills at the next layer up - their operational capacity sat above what was being displaced, and up they climbed. The cluster that has arrived now doesn’t displace a specific skill. Instead it generalises across the operations the climbing itself runs on - the abstracting, comparing, planning, and synthesising that moved a worker from one layer of work to the next. The hint is in the industrial language - we literally “train models”. There is no next layer to climb to, because the capacity for climbing is what’s being targeted.
That’s an unusual structural position. The evidence that the shape of automation has changed. It means the upward absorption mechanism that worked for five generations doesn’t have anywhere to push to. The layer it kept opening above isn’t there anymore.

Meanwhile, the downward direction is blocked too. Physical work plateaued at around 20% of US employment in the 1970s and stayed there. Embodied work plateaued at around 30% in the same period. Those categories didn’t shrink because they didn’t matter. They shrank because mechanisation cleared specific work from below and the wedge pushed workers up. The supply infrastructure that supports embodied and physical categories (apprenticeship programs, trades training, regional employment patterns) atrophied as the wedge ran. Three decades writing software doesn’t translate into a year-one apprenticeship in plumbing, electrical, or HVAC, and the few people who try, they lose the income premium that supported their household. The institutional capacity to “retrain at scale” into physical and embodied categories was disbanded across the 1980s and 1990s. The customer base for many of those trades is itself in the segment being targeted directly too - middle-class knowledge workers paying for residential building work, dental cosmetics, professional services, etc. Contraction in the targeted segment compresses demand in the categories displaced workers might in principle migrate into.
Of course, there are some carve-outs. Work the cluster targets weakly or not at all. Physical-effector work that actually moves matter in unstructured environments. Embodied-tacit work at master-tradesperson level requiring years of contextual sensorimotor refinement. Authority and accountability roles where the consequence of being wrong creates personal liability that doesn’t transfer to a system. Access and property-bound roles where the work depends on legally-bound permissions or relationships. Provenance and co-presence work where the value is in the human source itself. Stacked together they’re a meaningful share of remaining employment. But they aren’t going to grow and absorb the displaced symbolic workers the way the upward direction was.
This is the structural shape of a cluster operating at the ladder’s step of the upward ratchet. The mechanism that absorbed five generations of displaced labour worked because human operational capacity sat above the things being displaced. When the cluster operates at the level of that capacity itself, the mechanism doesn’t have somewhere to push to. There isn’t a “somewhere” it can be defined against.
What real evidence looks like
You don’t have to take my word for any of this.
The strongest signals are showing up in firm-level economics first - at the firms with the best information about what AI can actually do.
For most of SaaS history the compute-to-labour ratio at leading software firms sat at roughly 1:5. A dollar of compute for every five dollars of labour. Engineers, salespeople, customer success, operations. That’s how software companies grew through the 2000s and 2010s.
The AGI Labs’ forward operating profiles invert that. OpenAI’s compute to labour runs around 50:1. A 250-fold reversal in the structural ratio. Not an efficiency improvement. Not a margin gain. A reversal.
The same signature shows up across the cluster’s leading firms. NVIDIA earns around $5 million per employee, about ten times the typical SaaS company. The Mag7 plus NVIDIA grew aggregate capital expenditure from $82 billion in 2019 to $385 billion in 2025. Their 2026 aggregate guidance lands at $620-680 billion. Cumulative Mag7 layoffs through April 2026 run 155-170 thousand.
Revenue per worker at these firms is climbing sharply. Not because the workers got more productive. But because the lever isn’t the worker. It’s the compute. These ratios are not proof of labour substitution on their own - capex can reflect strategic buildout and expected demand. But they are exactly the kind of firm-level operating signature we would expect if compute is becoming the central production input.
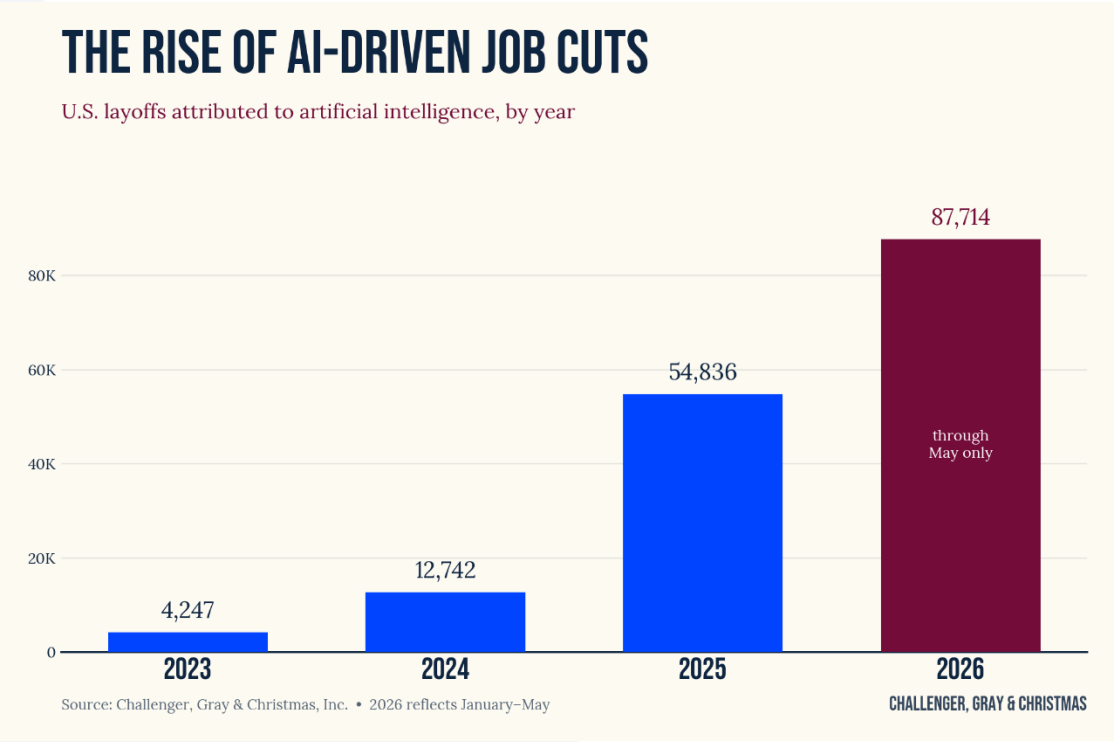
In April 2026, Meta cut roughly 8,000 roles with explicit reference to AI-driven productivity gains. Earlier rounds across the Mag7 had been framed as efficiency or post-pandemic correction. Then Meta called out AI as the reason. That was the moment AI-attribution-via-layoffs became something a publicly-listed firm could state plainly to shareholders without share-price punishment. Cloudflare, Microsoft, Salesforce, Intuit, Standard Chartered, HSBC, Cisco, Cognizant - several others followed in the weeks after with similar framing. By mid-2026 the pattern is established across banking, networking hardware, fintech, healthcare-IT vendors, IT services, BigLaw, and management consulting.
I’ve written previously about this pattern as #substituchurn.
The frontier AI labs are the cleanest place to look, for three reasons. They know what their own tools can do - including the internal models still 6-12 months from release. They are directly exposed to whether AI can substitute for the junior engineering work they themselves do. And they run heavily in-person operations by deliberate choice (Anthropic and OpenAI in San Francisco, Google DeepMind in London) which makes the work-from-home organisational-frictions story largely inapplicable.
What these firms are doing is consistent with the substitution prediction. Anthropic does not run a summer internship program. OpenAI is targeting much slower headcount growth than its historical trajectory, with Sam Altman explicitly attributing this to AI capability gains. Demis Hassabis at Davos in February 2026 said “I think we are going to see this year the beginnings of maybe impacting junior-level jobs and internships”. And across the broader tech industry, Q1 2026 layoffs ran at 47.9% AI-attributed, a 5-6× jump from sub-8% across 2025.
These firms are at the leading edge of AI capability. They are less exposed to the broad WFH confound than the remote-heavy knowledge-work occupations in the exposure literature. And they are visibly redistributing hiring away from junior generalists toward senior researchers and specialists. That is the compositional signature this argument predicts, appearing at the source, where the work-from-home confound that complicates the broader literature does not apply.
The most direct disclosure comes from Anthropic itself. In May 2026 they published “When AI Builds Itself”, reporting that Claude now authors over 80% of code merged into production at Anthropic, and that engineers ship 8× more code per quarter than they did in 2024. These are not third-party measurements. They are the lab’s own disclosure of what their tools are doing inside the lab - which is exactly the revealed-preference signature this argument has been pointing at.
The same piece also undercuts the augmentation framing it leans on. The standard “humans handle judgment, AI handles execution” line - the soft-landing scenario where humans remain in charge of direction-setting while AI does the work - that requires direction-setting itself to be a stable human-reserved function. But the data Anthropic reports says it isn’t. Claude now suggests better next research steps than humans 64% of the time, up from 51% just a year earlier. The function the soft-landing scenario reserves for humans is being absorbed in real time. If you draw the line forward at the current rate, the human-direction-setter equilibrium is a few model releases away from being indefensible on its own terms. And their comment “we could expect to see significant productivity multipliers on each person in this organization. 100-person companies could do the work of 10,000- or 100,000-person organizations.” suggests the scale of displacement we may be looking at very soon.
But what about the cohort-pattern evidence?
In 2025, Erik Brynjolfsson and his Stanford collaborators published “Canaries in the Coal Mine”, working from ADP payroll data covering tens of millions of US workers, by occupation and age cohort, across multiple years. The headline finding: among workers in occupations highly exposed to generative AI, the 22-25 age cohort saw employment fall around 20% from late 2022 through mid-2025, while older cohorts in the same occupations didn’t see the same fall. Three replications since the Canaries paper found the same cohort pattern - Anthropic’s Economic Index work finds a 14% drop in the job-finding rate for under-25s in AI-exposed occupations through early 2026, Mahieu’s May 2026 paper using Flanders administrative vacancy data finds entry-level vacancies in high-exposure occupations down around 23% at peak adoption, and Maasoum and Lichtinger’s May 2026 paper using US résumé and job-posting data across 62 million workers and 285,000 firms finds companies posting “AI integrator” roles see junior headcount drop 9% within six quarters with senior employment stable.
This is the cohort-pattern evidence most frequently cited as proof of AI substitution. But it deserves a careful look, because the picture is more complicated than the headline numbers suggest.
In May 2026 Lambert and Schindler at LSE and the Ellison Institute of Technology published The Broken Ladder, using 243 million new-hire records and 407 million job postings across the US, UK, Canada and Australia. They show that the occupation-level generative-AI exposure indices these cohort-pattern studies rely on are 0.77 Spearman-correlated with occupation-level work-from-home exposure - the same occupations sit at the top of both rankings, and the same at the bottom. When they run joint difference-in-differences with both exposures entered together as co-treatments, the work-from-home effect remains robust while the AI-exposure effect attenuates to statistical insignificance. Their reading: the cohort signal is plausibly picking up work-from-home organisational frictions rather than AI substitution.
On the methodology, they have a real point. The cohort-pattern studies above share an identification problem with the rapid post-pandemic shift to remote work. And there’s a deeper issue too. The kind of AI tooling that could plausibly substitute for a junior software developer (reasoning models capable of multi-step planning, coding harnesses capable of executing it autonomously) only became mainstream from early to mid 2025. Before that, the substitutive capability genuinely wasn’t there. So the junior-hiring decline these cohort-pattern studies observe across 2023 and 2024 is extremely unlikely to be AI substitution. Work-from-home organisational frictions, the 2022-23 rate-hike cycle, the venture-funding reversal, and the tech-sector restructuring that started in late 2022 are far more plausible drivers for that window. The substitution case was always going to make its empirical bid from late 2025 forward. I’ve worked through the Lambert-Schindler analysis in detail in a separate post, “Did AI or WFH break the career ladder?”, including where their own data is consistent with the substitution story. But on the narrow question of whether the cohort-pattern studies through 2024 prove AI substitution though, I now think the honest answer is they don’t.
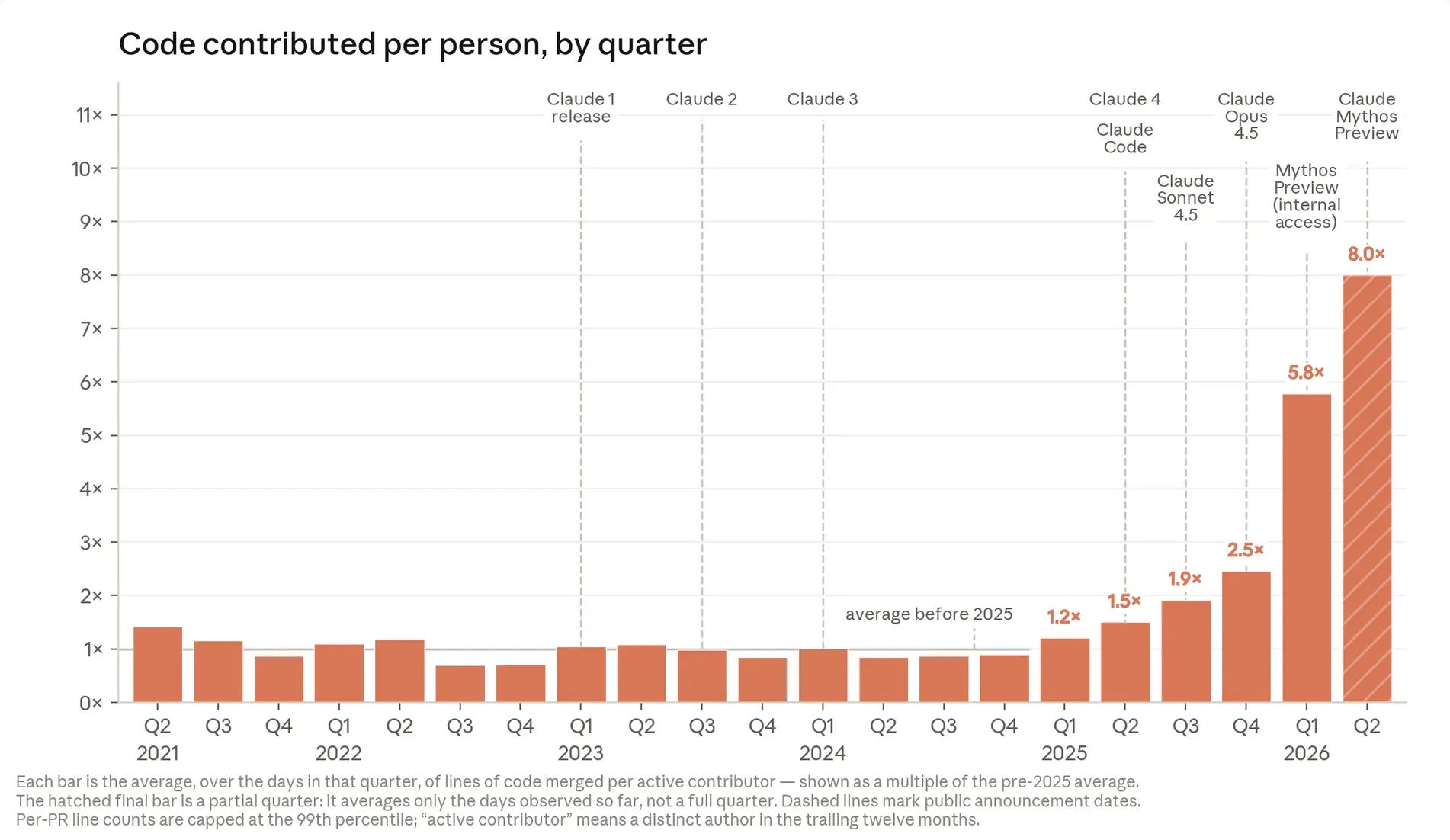
What does survive is the firm-level signature above, the frontier-lab evidence, and the leading-indicator data starting to emerge from the BLS QCEW Q4 2025 release published on June 2 2026. The national aggregate (+0.2% YoY employment, +4.2% YoY wages) is broadly consistent with the augmentation baseline continuing. But the supersector breakdown is more interesting. The Information sector - one of the most AI-exposed of the NAICS supersectors, covering software publishers, data processing, telecommunications, and related industries - shows employment down 2.2% YoY and wages up 6.9% YoY. That gap is consistent with the compositional signature this argument predicts: junior tier substituted, senior tier remains, average wage rises.
But one quarter is not decisive - the aggregate-level test is Q1 and Q2 2026 QCEW (released August and December 2026). And it is the first sector-level signal of the post-shift environment.
The signals from where capability has arrived first (the frontier labs) and where the work-from-home confound doesn’t apply, all line up with what this argument predicts. The aggregate-economy signal at supersector level is just starting to emerge. Multiple quarters of QCEW data through 2026 will read directly on whether the pattern compounds or stabilises.
Three traditions land in the same place
There’s one more thing about this argument that’s worth contemplating.
Newell and Simon, working in artificial intelligence in the 1970s, located intelligence at the level of symbolic operations.
Mokyr, working in economic history on what actually drives durable knowledge growth, located the engine at the same level.
Chollet, working in machine learning fifty years after Newell and Simon, defines intelligence as efficiency at acquiring skills - operations all the way down.
Three different fields. Three different methods. Three different starting questions. That convergence is why I keep coming back to this key idea.
It’s the part of this argument I find hardest to dismiss. You can argue with Mokyr’s analysis of the industrial revolution. You can disagree with Chollet’s definition of intelligence. You can challenge Newell and Simon’s symbolic-systems hypothesis. But when three traditions anchored in different bodies of primary data independently identify the same underlying mechanism, that’s harder to wave away than any single tradition’s claim would be.
So I’m not asking you to believe this is correct. I’m asking you to take it seriously enough that you watch the signals that would tell us if it is.
What would tell us this is wrong?
Here’s what would tell us that task-AGI Level 3 displacement isn’t actually structural, or that process-AGI development isn’t compounding toward Level 5 structural transformation.
If the appearance of a high-abstraction occupational category absorbing displaced workers at scale - more than half a million across two to three years, in a category that didn’t exist at meaningful size in 2024. AI-coordination, AI-evaluation, and AI-orchestration roles are the candidates discussed most often - and they are also becoming embedded in agentic harness. None has reached anything near that scale.
If physical-generalisation arrived first. If general-purpose embodied intelligence cleared the unstructured-environment threshold before frontier models cleared further symbolic-operation thresholds, the asymmetry that this whole argument hinges on inverts. However, this raises a whole new discussion.
If capability progression plateaued on agentic benchmarks. A multi-quarter flat reading on benchmarks that test multi-step agentic operations on real tasks, with frontier models having full context and tool access. That would suggest the cluster’s reach into the operations layer is shallower than it looks.
If the augmentation-to-automation balance fails to shift in post-2025 data through Q1-Q2 2026 QCEW (released August and December 2026), or if the Information sector signal observed in Q4 2025 reverts to growth or wage compression replaces the wage spike, then this analysis weakens.
If the Stanford Canaries cohort signature recovered toward its late-2022 baseline. A 22-25 cohort employment rebound to within five percentage points of the peak in exposed occupations by 2027-2028, with no capability regression behind it. That would indicate the cohort signal was a transient pattern rather than the leading edge of something structural. This would also be a strong confirmation of the WFH analysis for this too.
So far (as of mid-2026), none of these counter-signals have appeared. No new high-abstraction cluster is absorbing labour at scale. And frontier models continue to clear thresholds rather than plateau, with new capabilities arriving too.
I hope my analysis is wrong…
This is not a conclusion - and personally I really do hope that it is wrong. But this is an idea I keep coming back to because the evidence keeps lining up where it predicted, and because the things that would falsify it have not happened.
If the 22-25 cohort recovers, or a new occupational cluster absorbs displaced workers at scale, or frontier models plateau on agentic benchmarks for two consecutive quarters, then I’ll be posting about that. The point here is not to be right. It’s to clearly call out this pattern, the scenarios it projects and objectively analyse the updates when new evidence comes in.
One more signal worth flagging. As I mentioned earlier, in May 2026, Anthropic (arguably the most safety-focused of the frontier labs) published “When AI Builds Itself” arguing that the trajectory now warrants serious consideration of coordinated industry slowdown across multiple frontier labs in multiple countries, and acknowledging directly that “It is difficult to predict what the economy looks like if human labor stops being competitive.” That is a leading lab with strong commercial reasons not to make this argument, making it anyway. When the firms building this trajectory start putting coordinated slowdown on the table, the labour-market implications stop being a fringe concern.
The story I keep telling people who ask me “what are you actually worried about?” is this. Task-AGI (breadth across tangible tasks) is already substituting for entry-level work at the firms where capability has arrived first, with the wider economic signal just starting to emerge. The labs are reporting this progress accurately. This part is real and already visible in the firm-level and frontier-lab data right now. The deeper story underneath it is process-AGI (generalisation across the operations all those tasks sit on) developing toward Level 5, where the structural transformation overtakes incremental substitution. Both are reshaping work. Both are worth watching. And what’s being targeted by both are the operations that, until recently, were your only real cognitive advantage in your career.
Wow! Great insights.